You start at a new company. Everyone else has been there 7-8 years. They know which Jira project holds what, which wiki section has the real answer vs the abandoned draft, which Confluence page to ignore. They have muscle memory for the whole system. You don't.
So every task becomes a scavenger hunt. Where does this rule live? Is it in the code? In Jira? In OneNote? In someone's head? You find one doc that says "max LTV is 120%." Another says "110% for vehicles older than 5 years." The code says "125%." Three different answers. Which one is right?
The default fallback is always "just check the code." Hindi ko ma-trust ang code. The code might have bugs. The code might not even have the rule in it. Code is evidence, not truth.
A platform where you can ask "what's the rule for X?" and get an answer that pulls from everywhere — Jira tickets, wiki pages, local docs, code, tests — with sources, so you can see where each piece of the answer came from.
And once a human resolves the conflict, that resolution becomes a permanent rule. Every future query answers from it first. The original sources become references, not the truth anymore. The AI can draft, but only a human can approve.
1. Business Rules — this is the truth
2. Workflow Definitions — how things should move
3. Tests — what was actually validated
4. Code — might have bugs, NOT the truth
5. Production Telemetry — what is actually happening
Most tools treat code as the source of truth. This one doesn't. Code is near the bottom. The platform answers from the rule first and shows code as supporting evidence, not the other way around. That's the thing that bites new developers most — we default to reading code, and then we accidentally code to whatever bug already exists.
It works. From zero to a working chat in one day. Running locally with open-weight models on my laptop CPU — no API calls, no data leaves the network. Answers questions about my actual codebase with source citations. Streams token by token.
Then I kept building. Knowledge graph, code review mode, business rules extraction, conflict detection. Each day added a real capability, not just polish.
It's not ready to show yet. But the architecture is sound, the retrieval actually works, and the conflict detection is the part I'm proudest of. Name reveal coming when it's ready.
The knowledge graph
64 nodes, 62 edges. Repos, commits, authors, files, rules, documents — all connected. Color-coded by type. Built an in-app force-directed graph viewer from scratch — no external library. Pan, zoom, drag a node and the physics reflows. Click for detail.
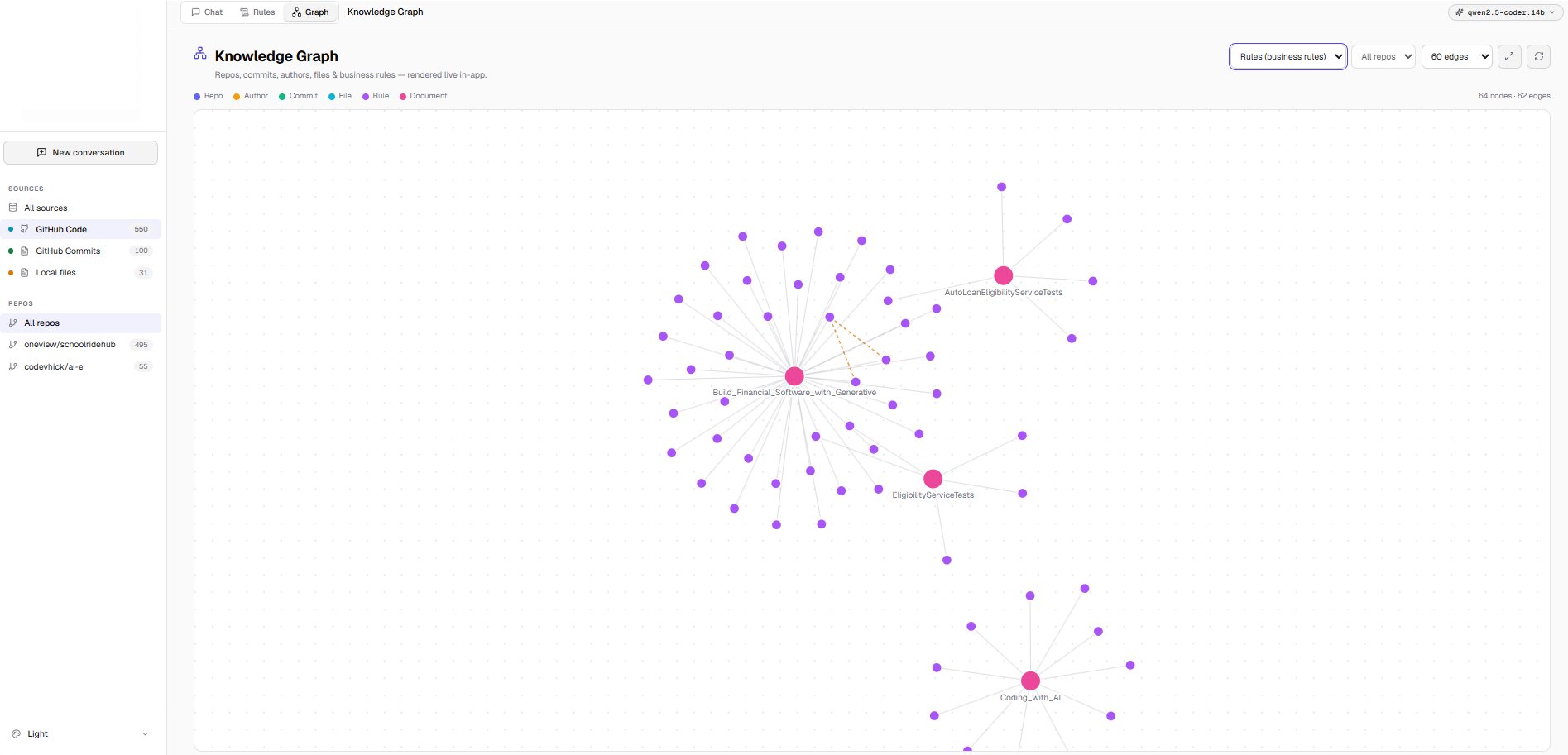
Knowledge graph — rules (purple), documents (pink), files (blue), with overlap edges (amber dashed)
Build Log
Day 1 — All planning, no code
May 27, 2026
Honest reason I'm building this: I'm three months into a new company and everyone else has been there 7-8 years. They have muscle memory for which Jira project holds what, which wiki section has the real answer. I don't. Walang shortcut para sa decade of institutional knowledge.
Every time I get a task, I have no idea where the rules actually live. And even when I find the right doc, I still have to learn the whole flow — how the workflow moves end to end, the state on each step, all the bugs that have been fixed and why they were fixed that way. None of that is in any single page.
Today was all docs. Scope definition, requirements, architecture, detailed design, implementation plan. A lot of writing. But I needed to think through what this thing is before opening a code editor.
Decisions locked: Python backend (the AI ecosystem is basically all Python, fighting it is dumb), React + TypeScript frontend, local LLM first via Ollama, pluggable providers for Claude/OpenAI, read-only connectors only (the platform never modifies source systems — non-negotiable), and two development tracks: Knowledge Platform first (no AI), then layer AI on top.
Day 2 — Cutting scope and two features I refused to cut
May 28, 2026
Still no code. But the scope went from 26 weeks to 20. Pushed Azure Application Insights, the issue discovery engine, PDF connector, and exec dashboards to future versions.
Two things I would not let go:
Conflict detection. When two sources disagree, the platform surfaces both and asks a human to resolve it. Never picks one. Never synthesizes a confident answer from conflicting evidence. I sketched a resolution hierarchy: human-resolved beats authority level beats recency beats specificity.
Final Rule Registry. Once a human resolves a conflict, that resolution becomes a permanent rule. Every future query answers from it first. AI can draft, but only a human approves. No AI silently establishing "truth."
Day 3 — From zero to a working chat in one day
May 29, 2026
This morning I had no code. Tonight I have a working chat at localhost:5777 that answers questions about my codebase, streams token by token, shows source citations. Running qwen2.5-coder:14b on my laptop CPU. It actually answers correctly. Hindi ko ine-expect 'to.
What got built: pluggable LLM provider (5 backends, one env var switch), GitHub connector (read-only, merged PRs + source code), local file connector (PDFs, Markdown), chunker → embedder → vector store pipeline, search + chat with SSE streaming, health endpoint, React chat UI with 5 themes, responsive layout, CI pipeline.
Then the bugs
The README problem. Asked the platform "what does the README say about getting started?" It confidently said there was no README. Except there was. I wrote it. It was ingested. It was in the vector store. But the embedding model ranked 50 other chunks higher because semantically "README" looked like every other doc about setup. Pure semantic similarity is sometimes confidently wrong. Fixed with a name-boost: if the query mentions a term, boost chunks whose title contains it. 10 lines of code. README jumped to #1.
Windows asyncio + psycopg. psycopg async needs SelectorEventLoop. Windows defaults to ProactorEventLoop. Uvicorn forces Proactor. Switched to asyncpg. Kept psycopg for Alembic where sync is fine.
Postgres port conflict. Local PostgreSQL 15 on port 5432. Docker bound to the same port "successfully" but connections went to the wrong Postgres. Different password. Auth failed. Moved Docker to 5434. Hours lost to a port collision.
Lesson: Retrieval matters more than the model. Better embeddings or smarter retrieval beats a bigger model for most RAG quality problems. And pluggable abstractions pay off fast — switching from psycopg to asyncpg took 10 minutes because the DB layer was already isolated.
Day 4 — Skills, modes, graph, and the system prompt that was too strict
May 30, 2026
Two sessions. The first built the graph + skills infrastructure. The second was a UX deep-dive triggered by actually trying to use the platform the way I'd been describing it.
The graph landed. Commit ingestion from GitHub. Each commit becomes a node with SHA, message, author, files changed. (Author)-[:AUTHORED]->(Commit)-[:TOUCHES]->(File). After running: 564 nodes, 674 relationships. The graph went from "infrastructure-only" to "actually queryable" in one afternoon.
Skills/Modes picker. Code Review pulls 12 chunks, Chat pulls 6. A mode switcher in the topbar, persisted to localStorage. When I review code, answers come back structured into MUST FIX / SHOULD FIX / NICE TO HAVE. That feedback loop is the difference between "RAG demo" and "tool I'll actually use."
Code Review got rewritten. I asked the platform to review a controller in a real codebase. The result flagged bugs and design issues but missed the thing I actually cared about: race conditions in async code. So I rewrote Code Review to put Concurrency & Race Conditions as section #1. Specific C# / React / Python failure modes for each. Concurrency findings always go to MUST FIX, never NICE TO HAVE. Not a generic best practice — a project-specific rule saved to memory so it persists.
The system prompt that was too strict
Asked: "What are the best practices for error handling in Python?" Answer: "I couldn't find anything relevant." Six chunks about agent design came back in the sources — a book about AI frameworks that absolutely covers error handling patterns. But the system prompt said "if the context does not contain the answer, say so plainly — never fabricate." The LLM read that as refuse-by-default.
Fixed with a three-case taxonomy: (1) context answers the question → answer with citations, (2) context covers the topic but doesn't fully answer → summarize what the sources DO say, state what's missing, (3) context is unrelated → say so. Re-asked. Real answer.
The one-character bug
tiktoken rejects strings containing <|endoftext|>. One PDF out of 3,643 had that literal token in its text. The error propagated through the chunker, got caught by the logger, which tried to print Unicode to the Windows cp1252 console, which failed with ANOTHER exception. The original error was hidden behind a second error from the error logger. Fix: one argument — disallowed_special=(). One character. Eight hours of "why is PDF #16 crashing."
Day 5 — Business rules, a graph you can see, and the bug that hid the whole answer
June 4, 2026
The day the platform filled in the top of its own hierarchy. I've been saying "business rules first, code last" since Day 1 — and the business rules layer was completely empty. Today it isn't.
Business rules extraction. The AI reads everything and produces candidate rules, each with provenance. Mines normative language — "must," "shall," "required," "forbidden." Tests count too: a passing test named Should_Block_Submission_After_60_Days is a business rule someone proved. First run: 7,022 chunks → 2,686 candidate rules. Noisy, pero that's what curation is for.
The honest surprise: 83% of extracted rules came from non-GitHub sources. The extractor is source-agnostic — it reads PDFs, exported docs, dummy tickets exactly like code.
In-app graph viewer. Built my own — a hand-rolled SVG force-directed layout. Pan, zoom, drag nodes and the physics reflows. Color by type. No external graph library. Pulled the vendor name out of the UI — implementation details shouldn't leak to the user.
Rules in the graph with conflict detection. Two rules that share key topic words and carry different numbers → CONFLICTS_WITH (red edges). Near-identical wording → OVERLAPS (amber dashed). Click a node, see the shared words that triggered the link. Self-documenting noise — you click an overlap, see "shared: file, header, parse" and immediately know it's junk.
I wrote a dummy scenario to test: one minimum credit score rule stated five different ways across five sources — 620 in a policy doc, 640 in a training guide, 600 in a stale wiki, 620 in the code, and 635 from production data analysis. Plus a ticket where updating one origination rule silently broke two downstream validations. The graph turns "if I change this rule, what else breaks?" into a traversal instead of an incident.
The bug that hid the entire answer
Chat returned sources but no answer. Just citations, then nothing. Happened on both local model AND Claude. Looked like a frontend bug. It wasn't. The backend streamed 179 tokens fine. The real culprit: on Windows, the CLI passed the RAG prompt as a command-line argument. cmd.exe truncates at ~8KB. The huge prompt chopped off the output format flag, so Claude printed plain text that the JSON parser silently skipped. Zero tokens. Empty answer. No error. Fix: feed the prompt via stdin. No length limit.
What building this confirmed
1. Code is not the source of truth. I already knew this — it's why I built the platform. But watching it work proved me right. The first time the system pulled a rule from a Jira ticket that contradicted what the code was doing, I felt vindicated. Sabi ko na eh.
2. When sources disagree, don't pick one. This was the whole thesis. Building it out showed me how often real-world data actually conflicts — and how dangerous it is when tools quietly pick the highest-scoring answer and move on.
3. Retrieval matters more than the model. A smarter retrieval strategy beats a bigger model every time for RAG quality.
4. The value isn't the feature — it's making the feature legible. A graph nobody can see, a rule with no provenance, an empty answer with no error — each one was technically "working" and practically useless.
5. Every UX decision came from actually using the thing. The compact sources pill, the copy/download buttons, the system prompt rewrite — none of that was on a roadmap. It came from "this feels off" → fix → ship → next.
6. I'm building this because I wish I had it on day one. Kaya ko 'to ginagawa para sa next person na papasok sa team na hindi kailangang mag-grind katulad ko.
What's next
The rule approval workflow (BR2) — the trust gate where humans promote, edit, or deprecate rules. PR-style code reviews with risk-ranked files from the graph. Dependency edges in the graph so you can see "if I change this rule, what else breaks." And eventually — the name reveal.
Another platform. Another name I'm keeping to myself. Mamaya na. For now — the work is the pitch.